Autocorrect
There are a lot of words that are prone to being typed incorrectly, due to habit, sequence or just user error. This feature leverages your firmware to automatically correct these errors, to help reduce typos.
How does it work?
The feature maintains a small buffer of recent key presses. On each key press, it checks whether the buffer ends in a recognized typo, and if so, automatically sends keystrokes to correct it.
The tricky part is how to efficiently check the buffer for typos. We don’t want to spend too much memory or time on storing or searching the typos. A good solution is to represent the typos with a trie data structure. A trie is a tree data structure where each node is a letter, and words are formed by following a path to one of the leaves.
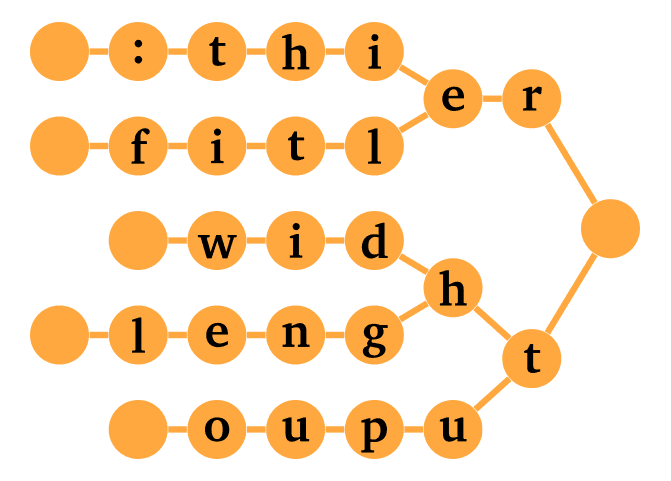
Since we search whether the buffer ends in a typo, we store the trie writing in reverse. The trie is queried starting from the last letter, then second to last letter, and so on, until either a letter doesn’t match or we reach a leaf, meaning a typo was found.
How do I enable Autocorrection
In your rules.mk, add this:
AUTOCORRECT_ENABLE = yesAdditionally, you will need a library for autocorrection. A small sample library is included by default, so that you can get up and running right away, but you can provide a customized library.
By default, autocorrect is disabled. To enable it, you need to use the AC_TOGG keycode to enable it. The status is stored in persistent memory, so you shouldn't need to enabled it again.
Customizing autocorrect library
To provide a custom library, you need to create a text file with the corrections. For instance:
:thier -> their
fitler -> filter
lenght -> length
ouput -> output
widht -> widthThe syntax is typo -> correction. Typos and corrections are case insensitive, and any whitespace before or after the typo and correction is ignored. The typo must be only the letters a–z, or the special character : representing a word break. The correction may have any non-unicode characters.
Then, run:
qmk generate-autocorrect-data autocorrect_dictionary.txtThis will process the file and produce an autocorrect_data.h file with the trie library, in the folder that you are at. You can specify the keyboard and keymap (eg -kb planck/rev6 -km jackhumbert), and it will place the file in that folder instead. But as long as the file is located in your keymap folder, or user folder, it should be picked up automatically.
This file will look like this:
// :thier -> their
// fitler -> filter
// lenght -> length
// ouput -> output
// widht -> width
#define AUTOCORRECT_MIN_LENGTH 5 // "ouput"
#define AUTOCORRECT_MAX_LENGTH 6 // ":thier"
#define DICTIONARY_SIZE 74
static const uint8_t autocorrect_data[DICTIONARY_SIZE] PROGMEM = {85, 7, 0, 23, 35, 0, 0, 8, 0, 76, 16, 0, 15, 25, 0, 0,
11, 23, 44, 0, 130, 101, 105, 114, 0, 23, 12, 9, 0, 131, 108, 116, 101, 114, 0, 75, 42, 0, 24, 64, 0, 0, 71, 49, 0,
10, 56, 0, 0, 12, 26, 0, 129, 116, 104, 0, 17, 8, 15, 0, 129, 116, 104, 0, 19, 24, 18, 0, 130, 116, 112, 117, 116,
0};Avoiding false triggers
By default, typos are searched within words, to find typos within longer identifiers like maxFitlerOuput. While this is useful, a consequence is that autocorrection will falsely trigger when a typo happens to be a substring of a correctly-spelled word. For instance, if we had thier -> their as an entry, it would falsely trigger on (correct, though relatively uncommon) words like “wealthier” and “filthier.”
The solution is to set a word break : before and/or after the typo to constrain matching. : matches space, period, comma, underscore, digits, and most other non-alpha characters.
| Text | thier | :thier | thier: | :thier: |
|---|---|---|---|---|
see thier typo | matches | matches | matches | matches |
it’s thiers | matches | matches | no | no |
| wealthier words | matches | no | matches | no |
:thier: is most restrictive, matching only when thier is a whole word.
The qmk generate-autocorrect-data commands can make an effort to check for entries that would false trigger as substrings of correct words. It searches each typo against a dictionary of 25K English words from the english_words Python package, provided it’s installed. (run python3 -m pip install english_words to install it.)
TIP
Unfortunately, this is limited to just english words, at this point.
Overriding Autocorrect
Occasionally you might actually want to type a typo (for instance, while editing autocorrect_dict.txt) without being autocorrected. There are a couple of ways to do this:
- Begin typing the typo.
- Before typing the last letter, press and release the Ctrl or Alt key.
- Type the remaining letters.
This works because the autocorrection implementation doesn’t understand hotkeys, so it resets itself whenever a modifier other than shift is held.
Additionally, you can use the AC_TOGG keycode to toggle the on/off status for Autocorrect.
Keycodes
| Keycode | Aliases | Description |
|---|---|---|
QK_AUTOCORRECT_ON | AC_ON | Turns on the Autocorrect feature. |
QK_AUTOCORRECT_OFF | AC_OFF | Turns off the Autocorrect feature. |
QK_AUTOCORRECT_TOGGLE | AC_TOGG | Toggles the status of the Autocorrect feature. |
User Callback Functions
Process Autocorrect
Callback function bool process_autocorrect_user(uint16_t *keycode, keyrecord_t *record, uint8_t *typo_buffer_size, uint8_t *mods) is available to customise incoming keycodes and handle exceptions. You can use this function to sanitise input before they are passed onto the autocorrect engine
TIP
Sanitisation of input is required because autocorrect will only match 8-bit basic keycodes for typos. If valid modifier keys or 16-bit keycodes that are part of a user's word input (such as Shift + A) is passed through, they will fail typo letter detection. For example a Mod-Tap key such as LCTL_T(KC_A) is 16-bit and should be masked for the 8-bit KC_A.
The default user callback function is found inside quantum/process_keycode/process_autocorrect.c. It covers most use-cases for QMK special functions and quantum keycodes, including overriding autocorrect with a modifier other than shift. The process_autocorrect_user function is weak defined to allow user's copy inside keymap.c (or code files) to overwrite it.
Process Autocorrect Example
If you have a custom keycode QMKBEST that should be ignored as part of a word, and another custom keycode QMKLAYER that should override autocorrect, both can be added to the bottom of the process_autocorrect_user switch statement in your source code:
bool process_autocorrect_user(uint16_t *keycode, keyrecord_t *record, uint8_t *typo_buffer_size, uint8_t *mods) {
// See quantum_keycodes.h for reference on these matched ranges.
switch (*keycode) {
// Exclude these keycodes from processing.
case KC_LSFT:
case KC_RSFT:
case KC_CAPS:
case QK_TO ... QK_ONE_SHOT_LAYER_MAX:
case QK_LAYER_TAP_TOGGLE ... QK_LAYER_MOD_MAX:
case QK_ONE_SHOT_MOD ... QK_ONE_SHOT_MOD_MAX:
return false;
// Mask for base keycode from shifted keys.
case QK_LSFT ... QK_LSFT + 255:
case QK_RSFT ... QK_RSFT + 255:
if (*keycode >= QK_LSFT && *keycode <= (QK_LSFT + 255)) {
*mods |= MOD_LSFT;
} else {
*mods |= MOD_RSFT;
}
*keycode &= 0xFF; // Get the basic keycode.
return true;
#ifndef NO_ACTION_TAPPING
// Exclude tap-hold keys when they are held down
// and mask for base keycode when they are tapped.
case QK_LAYER_TAP ... QK_LAYER_TAP_MAX:
# ifdef NO_ACTION_LAYER
// Exclude Layer Tap, if layers are disabled
// but action tapping is still enabled.
return false;
# endif
case QK_MOD_TAP ... QK_MOD_TAP_MAX:
// Exclude hold if mods other than Shift is not active
if (!record->tap.count) {
return false;
}
*keycode &= 0xFF;
break;
#else
case QK_MOD_TAP ... QK_MOD_TAP_MAX:
case QK_LAYER_TAP ... QK_LAYER_TAP_MAX:
// Exclude if disabled
return false;
#endif
// Exclude swap hands keys when they are held down
// and mask for base keycode when they are tapped.
case QK_SWAP_HANDS ... QK_SWAP_HANDS_MAX:
#ifdef SWAP_HANDS_ENABLE
if (*keycode >= 0x56F0 || !record->tap.count) {
return false;
}
*keycode &= 0xFF;
break;
#else
// Exclude if disabled
return false;
#endif
// Handle custom keycodes
case QMKBEST:
return false;
case QMKLAYER:
*typo_buffer_size = 0;
return false;
}
// Disable autocorrect while a mod other than shift is active.
if ((*mods & ~MOD_MASK_SHIFT) != 0) {
*typo_buffer_size = 0;
return false;
}
return true;
}TIP
In this callback function, return false will skip processing of that keycode for autocorrect. Adding *typo_buffer_size = 0 will also reset the autocorrect buffer at the same time, cancelling any current letters already stored in the buffer.
Apply Autocorrect
Additionally, apply_autocorrect(uint8_t backspaces, const char *str, char *typo, char *correct) allows for users to add additional handling to the autocorrection, or replace the functionality entirely. This passes on the number of backspaces needed to replace the words, as well as the replacement string (partial word, not the full word), and the typo and corrected strings (complete words).
TIP
Due to the way code works (no notion of words, just a stream of letters), the typo and correct strings are a best bet and could be "wrong". For example you may get wordtpyo & wordtypo instead of the expected tpyo & typo.
Apply Autocorrect Example
This following example will play a sound when a typo is autocorrected and execute the autocorrection itself:
#ifdef AUDIO_ENABLE
float autocorrect_song[][2] = SONG(TERMINAL_SOUND);
#endif
bool apply_autocorrect(uint8_t backspaces, const char *str, char *typo, char *correct) {
#ifdef AUDIO_ENABLE
PLAY_SONG(autocorrect_song);
#endif
for (uint8_t i = 0; i < backspaces; ++i) {
tap_code(KC_BSPC);
}
send_string_P(str);
return false;
}TIP
In this callback function, return false will stop the normal processing of autocorrect, which requires manually handling of removing the "bad" characters and typing the new characters.
WARNING
IMPORTANT: str is a pointer to PROGMEM data for the autocorrection. If you return false, and want to send the string, this needs to use send_string_P and not send_string nor SEND_STRING.
You can also use apply_autocorrect to detect and display the event but allow internal code to execute the autocorrection with return true:
bool apply_autocorrect(uint8_t backspaces, const char *str, char *typo, char *correct) {
#ifdef OLED_ENABLE
oled_write_P(PSTR("Auto-corrected"), false);
#endif
#ifdef CONSOLE_ENABLE
printf("'%s' was corrected to '%s'\n", typo, correct);
#endif
return true;
}Autocorrect Status
Additional user callback functions to manipulate Autocorrect:
| Function | Description |
|---|---|
autocorrect_enable() | Turns Autocorrect on. |
autocorrect_disable() | Turns Autocorrect off. |
autocorrect_toggle() | Toggles Autocorrect. |
autocorrect_is_enabled() | Returns true if Autocorrect is currently on. |
Appendix: Trie binary data format
This section details how the trie is serialized to byte data in autocorrect_data. You don’t need to care about this to use this autocorrection implementation. But it is documented for the record in case anyone is interested in modifying the implementation, or just curious how it works.
What I did here is fairly arbitrary, but it is simple to decode and gets the job done.
Encoding
All autocorrection data is stored in a single flat array autocorrect_data. Each trie node is associated with a byte offset into this array, where data for that node is encoded, beginning with root at offset 0. There are three kinds of nodes. The highest two bits of the first byte of the node indicate what kind:
- 00 ⇒ chain node: a trie node with a single child.
- 01 ⇒ branching node: a trie node with multiple children.
- 10 ⇒ leaf node: a leaf, corresponding to a typo and storing its correction.
Branching node. Each branch is encoded with one byte for the keycode (KC_A–KC_Z) followed by a link to the child node. Links between nodes are 16-bit byte offsets relative to the beginning of the array, serialized in little endian order.
All branches are serialized this way, one after another, and terminated with a zero byte. As described above, the node is identified as a branch by setting the two high bits of the first byte to 01, done by bitwise ORing the first keycode with 64. keycode. The root node for the above figure would be serialized like:
+-------+-------+-------+-------+-------+-------+-------+
| R|64 | node 2 | T | node 3 | 0 |
+-------+-------+-------+-------+-------+-------+-------+Chain node. Tries tend to have long chains of single-child nodes, as seen in the example above with f-i-t-l in fitler. So to save space, we use a different format to encode chains than branching nodes. A chain is encoded as a string of keycodes, beginning with the node closest to the root, and terminated with a zero byte. The child of the last node in the chain is encoded immediately after. That child could be either a branching node or a leaf.
In the figure above, the f-i-t-l chain is encoded as
+-------+-------+-------+-------+-------+
| L | T | I | F | 0 |
+-------+-------+-------+-------+-------+If we were to encode this chain using the same format used for branching nodes, we would encode a 16-bit node link with every node, costing 8 more bytes in this example. Across the whole trie, this adds up. Conveniently, we can point to intermediate points in the chain and interpret the bytes in the same way as before. E.g. starting at the i instead of the l, and the subchain has the same format.
Leaf node. A leaf node corresponds to a particular typo and stores data to correct the typo. The leaf begins with a byte for the number of backspaces to type, and is followed by a null-terminated ASCII string of the replacement text. The idea is, after tapping backspace the indicated number of times, we can simply pass this string to the send_string_P function. For fitler, we need to tap backspace 3 times (not 4, because we catch the typo as the final ‘r’ is pressed) and replace it with lter. To identify the node as a leaf, the two high bits are set to 10 by ORing the backspace count with 128:
+-------+-------+-------+-------+-------+-------+
| 3|128 | 'l' | 't' | 'e' | 'r' | 0 |
+-------+-------+-------+-------+-------+-------+Decoding
This format is by design decodable with fairly simple logic. A 16-bit variable state represents our current position in the trie, initialized with 0 to start at the root node. Then, for each keycode, test the highest two bits in the byte at state to identify the kind of node.
- 00 ⇒ chain node: If the node’s byte matches the keycode, increment state by one to go to the next byte. If the next byte is zero, increment again to go to the following node.
- 01 ⇒ branching node: Search the branches for one that matches the keycode, and follow its node link.
- 10 ⇒ leaf node: a typo has been found! We read its first byte for the number of backspaces to type, then pass its following bytes to send_string_P to type the correction.
Credits
Credit goes to getreuer for originally implementing this here. As well as to filterpaper for converting the code to use PROGMEM, and additional improvements.